Machine Learning

Problema de Regresión
Prompt:
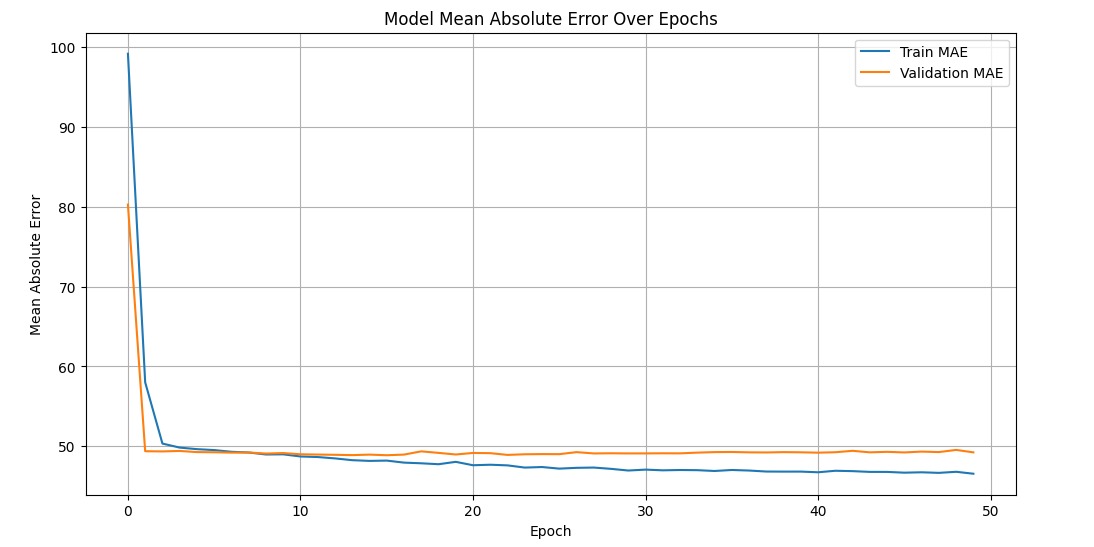
Eres un experto en Machine Learning, Redes Neuronales Artificiales e Inteligencia Artificial, soy estudiante de la Universidad Central Del Ecuador cursando el tercer semestre con la materia de Estadística y Probabilidad con todas esas herramientas necesito que me ayudes a desarrollar un modelo de clasificación basado en una red neuronal artificial para predecir contaminante (mg/kg) a partir de'Rainfall_mm', 'Soil_pH', 'Temperature_C', 'Humidity_%', 'Soil_Organic_Matter_%', 'Region', 'Crop_Type' y para esta variable transfórmala a cuantitativa usando codificación binaria (0,1). Normaliza los datos para que estén en una misma escala entre 0 y 1, balancea los datos para que no haya preferencia o sesgos. El dataset "soil_pollution_diseases (2).csv" se encuentra almacenado de forma temporal en Archivos. Genera el código en lenguaje de programación Python, solo con comentarios únicamente en idioma español, cada etapa debe estar y ser visible en una única celda y no omitas ni te saltes ninguna parte sin excepción, importa todas las librerías que necesites desde el inicio. presenta de forma explícita la gráfica de pérdida (loss) frente a las épocas para entrenamiento y validación. Asegura que las predicciones no sean irreales: la precipitación no puede ser negativa y toma el rango del dataset es decir de 0mm a 400mm. Finalmente, implementa una interfaz sencilla e interactiva dentro del notebook (por ejemplo, con ipywidgets) que permita ingresar valores de las variables de entrada y la precipitación (mm) presentando el resultado de forma clara y académica.
Problema de Clasificación:
Prompt:
Actúa como experto en Machine Learning, Redes Neuronales Artificiales y Python.
Soy estudiante de Ingeniería Ambiental y necesito desarrollar un modelo de clasificación multiclase que permita predecir el nivel de concentración de contaminante en el suelo (Bajo, Medio, Alto).
El dataset se encuentra en un archivo CSV llamado "pollution_diseases.csv" y contiene las siguientes variables:
- concentration
- pollutant_type
- soil_pH
- nearby_industry
- organic_matter
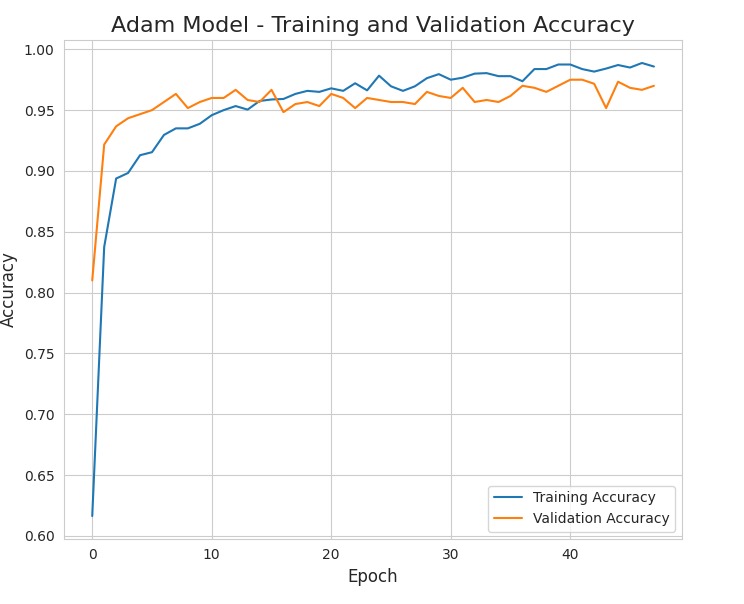
Requisitos del modelo:n Transformar la variable continua "concentration" en niveles categóricos (Bajo, Medio, Alto) usando cuantiles. Realizar análisis exploratorio básico y verificar si las clases están balanceadas. Aplicar One Hot Encoding a las variables categóricas. Normalizar las variables numéricas. Realizar Feature Engineering creando nuevas variables relevantes como: Interacción concentración × pH, Índice ambiental concentración / materia orgánica, Transformación logarítmica si hay asimetría Dividir el dataset en entrenamiento y prueba. Construir una red neuronal artificial con: Al menos 3 capas ocultas, Activación ReLU o LeakyReLU, Dropout para evitar overfitting. Usar un optimizador adecuado y comparar al menos dos (Adam y SGD). Incluir EarlyStopping para evitar sobreajuste. Graficar: Loss vs épocas. Mostrar matriz de confusión Evaluar si existe underfitting u overfitting analizando la curva. Incluir comentarios en español explicando cada paso. Generar una interfaz simple para realizar predicciones.
El código debe estar organizado por etapas claras y cada etapa en una celda independiente.